1.1 概念与要点
collections模块提供了Python内置容器的替代选择,这些数据结构针对特定场景进行了优化:
- defaultdict:自动初始化键值的字典
- OrderedDict:保持插入顺序的字典
- Counter:高效计数器
- deque:双端队列,支持O(1)复杂度的两端操作
- namedtuple:创建带有命名字段的元组子类
- ChainMap:将多个字典合并为单一视图
1.2 示例
from collections import defaultdict, Counter, deque, namedtuple
# defaultdict示例:自动初始化列表
word_count = defaultdict(int)
for word in ['apple', 'banana', 'apple']:
word_count[word] += 1# 无需检查键是否存在
# Counter示例:快速计数
inventory = Counter(apple=10, banana=5)
inventory.update(['apple', 'orange']) # 更新计数
# deque示例:高效双端操作
history = deque(maxlen=5) # 固定长度队列
history.extend([1,2,3])
history.appendleft(0) # 左侧添加元素
# namedtuple示例:自描述元组
Point = namedtuple('Point', ['x', 'y'])
p = Point(11, y=22)
print(p.x, p.y) # 通过名称访问
1.3 注意事项
defaultdictCounterdequenamedtuple创建后不可修改,需要可变结构时使用dataclass
1.4 小结
collections提供的高效数据结构能显著提升代码性能和可读性,特别适合处理复杂数据聚合任务。
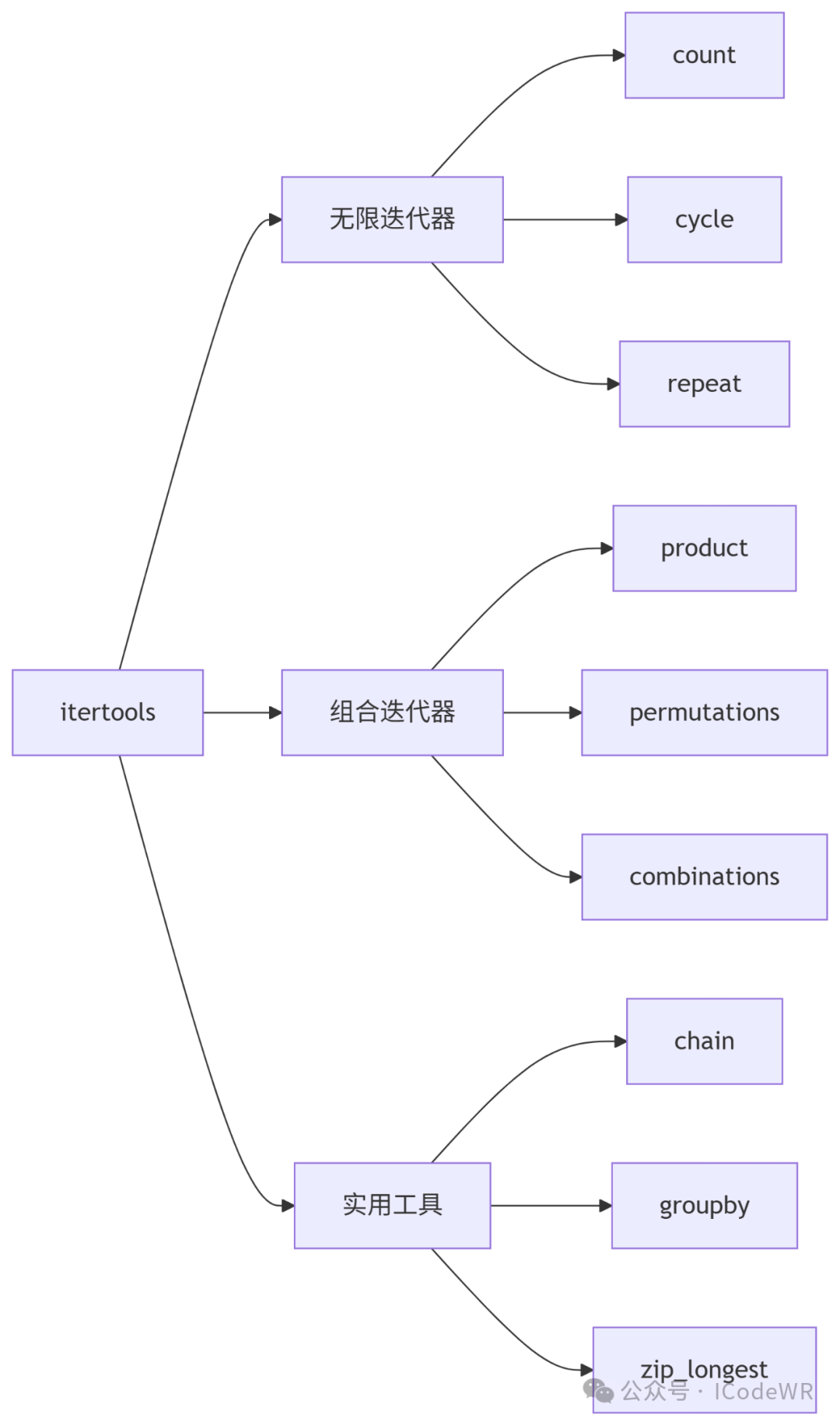
2.1 核心功能分类
2.2 应用示例
import itertools
# 无限迭代器:生成数字序列
for i in itertools.islice(itertools.count(10), 5):
print(i) # 10,11,12,13,14
# 组合迭代器:排列组合
print(list(itertools.permutations('ABC', 2))) # [('A','B'), ('A','C'), ...]
print(list(itertools.combinations('ABCD', 3))) # 3个元素的所有组合
# 分组操作
data = sorted([('A', 1), ('B', 2), ('A', 3)], key=lambda x: x[0])
for key, group in itertools.groupby(data, key=lambda x: x[0]):
print(f"{key}: {list(group)}")
# 链式迭代
iter1 = [1,2,3]
iter2 = ['a','b','c']
print(list(itertools.chain(iter1, iter2))) # [1,2,3,'a','b','c']
2.3 注意事项
- 无限迭代器需要终止条件(如
islice或takewhile) groupby
2.4 小结
itertools提供的高阶迭代器工具能优雅处理大数据流,避免内存溢出问题,特别适合数据处理管道。
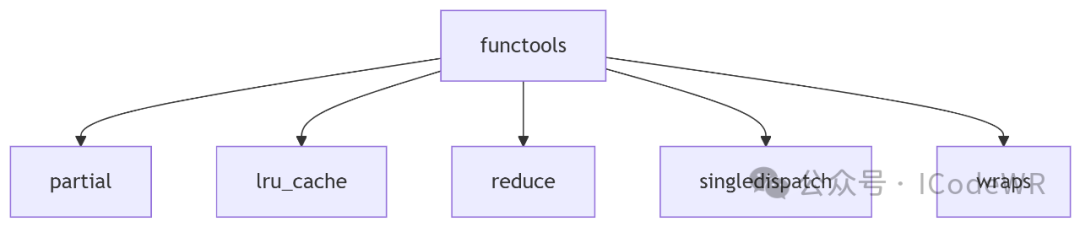
3.1 核心功能解析
3.2 示例
from functools import partial, lru_cache, reduce, singledispatch
# 偏函数:冻结部分参数
base_two = partial(int, base=2)
print(base_two('1010')) # 10
# 缓存优化:斐波那契数列
@lru_cache(maxsize=128)
deffibonacci(n):
return n if n < 2else fibonacci(n-1) + fibonacci(n-2)
# 累积计算
product = reduce(lambda x,y: x*y, range(1,6)) # 120
# 单分派泛型函数
@singledispatch
defprocess(data):
raise NotImplementedError("Unsupported type")
@process.register(str)
def_(text):
returnf"处理字符串: {text.lower()}"
@process.register(int)
def_(number):
returnf"处理数字: {number**2}"
print(process("Hello")) # 处理字符串: hello
print(process(5)) # 处理数字: 25
3.3 注意事项
lru_cachepartialsingledispatch
3.4 小结
functools提供函数式编程工具,能优化性能、简化代码结构,特别适合数学计算和API设计。
4.1 实用上下文工具
from contextlib import contextmanager, suppress, redirect_stdout
import os
# 自定义上下文管理器
@contextmanager
defcd(path):
"""安全切换目录的上下文管理器"""
old_path = os.getcwd()
os.chdir(path)
try:
yield
finally:
os.chdir(old_path)
# 使用示例
with cd('/tmp'):
print(os.getcwd()) # /tmp
print(os.getcwd()) # 返回原目录
# 忽略指定异常
with suppress(FileNotFoundError):
os.remove('non_existent.file')
# 重定向输出
with redirect_stdout(open('output.txt', 'w')):
print("保存到文件")
4.2 注意事项
4.3 小结
contextlib简化了资源管理代码,确保资源正确释放,使代码更健壮和安全。
5.1 datetime示例
from datetime import datetime, timedelta, timezone
# 时区处理
utc_now = datetime.now(timezone.utc)
beijing_tz = timezone(timedelta(hours=8))
beijing_time = utc_now.astimezone(beijing_tz)
# 时间运算
next_week = datetime.now() + timedelta(weeks=1)
# 精确计时
start = datetime.now()
# 执行操作...
elapsed = datetime.now() - start
print(f"耗时: {elapsed.total_seconds():.4f}秒")
5.2 日历操作
import calendar
# 生成月历
cal = calendar.TextCalendar()
print(cal.formatmonth(2023, 7))
# 日期计算
_, days_in_feb = calendar.monthrange(2023, 2)
print(f"2023年2月有{days_in_feb}天") # 28
5.3 注意事项
5.4 小结
datetime和calendar提供完整的日期时间处理方案,特别适合日志分析、定时任务等场景。
6.1 用法示例
import re
# 命名捕获组
text = "Date: 2023-07-20"
pattern = r"Date: (?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})"
match = re.search(pattern, text)
if match:
print(match.groupdict()) # {'year': '2023', 'month': '07', 'day': '20'}
# 编译正则提高性能
email_re = re.compile(r'[\w\.-]+@[\w\.-]+\.\w+')
emails = email_re.findall("Contact: a@b.com, x@y.org")
6.2 正则技巧
6.3 小结
re模块提供强大的文本处理能力,适合日志解析、数据清洗等复杂文本操作。
7.1 日志分析
from collections import Counter
import re
from datetime import datetime
defanalyze_logs(log_file):
ip_pattern = re.compile(r'(\d+\.\d+\.\d+\.\d+)')
date_pattern = re.compile(r'\[(\d{2}/\w{3}/\d{4})')
status_pattern = re.compile(r'HTTP/\d\.\d" (\d{3})')
ip_counter = Counter()
status_counter = Counter()
daily_requests = defaultdict(int)
withopen(log_file) as f:
for line in f:
if ip_match := ip_pattern.search(line):
ip_counter[ip_match.group(1)] += 1
if date_match := date_pattern.search(line):
date_str = date_match.group(1)
date = datetime.strptime(date_str, '%d/%b/%Y').date()
daily_requests[date] += 1
if status_match := status_pattern.search(line):
status_counter[status_match.group(1)] += 1
return {
'top_ips': ip_counter.most_common(5),
'status_codes': dict(status_counter),
'daily_requests': sorted(daily_requests.items())
}
7.2 数据批处理管道
from itertools import islice, chain
from functools import partial
import csv
defbatch_processor(data, process_func, batch_size=100):
iterator = iter(data)
while batch := list(islice(iterator, batch_size)):
yield process_func(batch)
defprocess_users(users):
return [{'name': u['name'].upper(), 'age': int(u['age'])+1} for u in users]
defread_csv(file_path):
withopen(file_path) as f:
return csv.DictReader(f)
# 构建处理管道
data_pipeline = chain(
read_csv('users.csv'),
partial(batch_processor, process_func=process_users),
lambda batches: (user for batch in batches for user in batch)
)
# 执行处理
for user in data_pipeline():
save_to_database(user)
选择合适的数据结构:
迭代器处理技巧:
性能优化:
资源管理:
代码可维护性:
通过掌握这些标准库的使用技巧,可以编写出更高效、简洁和可维护的Python代码。这些库经过充分优化和测试,是Python编程的坚实基础。
阅读原文:原文链接
该文章在 2025/7/18 10:51:34 编辑过






 400 186 1886
400 186 1886